To fetch or modify information through a GraphQL API, you need to write a request in a formatted way that follows a set of rules: it needs to be a JSON object and it must match the structure of the API’s schema.
Also, if GraphQL objects are the containers that give structure to the API, remember it it actually the fields that give access to information. So it is the fields that you want to query.
A simple GraphQL query operation
Here’s what a GraphQL query looks like:
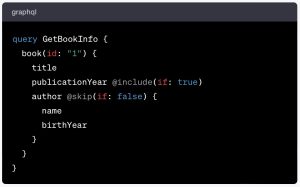
Let’s break it down.
All GraphQL requests begin with an indication of the operation’s root type. This can be either query, mutation or subscription. In the present case, we are writing a query operation, indicated in blue, on the first line of our example (if you are unfamiliar with GraphQL queries, mutations and subscriptions, I have a post explaining these notions right here)
Also on the first line is the operation name (GetBookInfo in our example). The operation name is a label that is given by the user (or the client app) that makes the request.
It has no real function in the request but it helps identify requests when you have two query operations listed one after the other (more in this further down).
If you have just one query operation, as in the example above, the operation name is optional.
Then comes a code block with the actual fields we want to query.
The first field (book in our example) is the top level field. It refers to the main element we want to access. In the present case, the book field allows us to access individual elements of a given Book object, such as its title, its year of publication and details on its author (remember the relationship between the book field and the Book object is defined in the schema).
Then come the fields that will return the data we want. In our example, these fields are title, publicationYear and author. Notice the indentation with the author’s name and birthYear.
Still with me? Perfect. You will also notice that the book top level field in our example has an argument (id in the present case). This argument allows us to specify which book we want to obtain information about. The arguments you may use for this top level field are specified in the schema.
Arguments have a value (in green in the example above). Here, it is the id value of the book we want to access.
Typically, an argument allows us to pass a parameter that will adjust the behavior and/or result of that field.
Further down, look at the publicationYear and author fields. These two fields have a directive (in gray): @include and @skip, respectively. These directives allow us to perform an action on the data we are requesting, before this data is displayed back.
Also, directives use arguments to allow us to pass the parameters we require to perform the action we want. In the present case, the @include directive will check if this book’s publicationYear field contains a value. If it does, it will include that field in the response. If not, it will eliminate that field from the response.
Likewise, the @skip directive will check if the author field contains data. If so, it will include this field and its sub-fields in the response. If not, it will skip the author field and its sub-fields altogether.
With all these items set, our query operation is ready to be sent. So what happens next ?
Well, the GraphQL server will typically return a response like this one (also formatted as a JSON object):
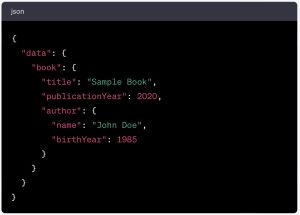
You can see the response is structured in the same way as our request, with the same indentations.
Another example of a GraphQL query
Let’s look at another example:
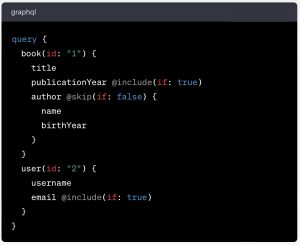
Here, we have a query operation with two top level fields (book and user). Each of these top level fields have their own arguments and sub-fields. Some of these sub-fields have a directive applied to them.
As mentioned above, since we are inside a single query operation, an operation name is not necessary.
The above query will typically return a response like this one:
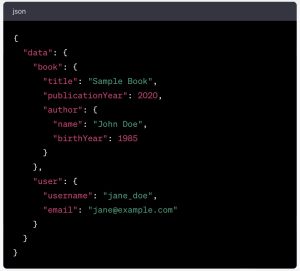
This shows you the power of GraphQL as a query language. With a single request, we can return data from the different objects we want, choosing the exact fields we want for each object (provided they are defined in the schema for this object – my apologies if I sound like a broken record). If these objects happen to have other fields that we didn’t ask for, these fields will be left out of the response, making for a lean and clean response.
Writing two queries one after the other
Remember what I mentioned early on about writing two queries? Well, there are situations where you may want to write two (or more) separate queries one after the other in the input field of your query tool (I’ll address query tools in a later post). This is what it would look like:
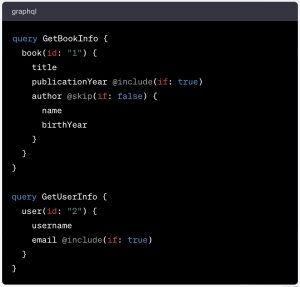
In that case, an operation name is required for each query. You will have to send these queries separately, so a name is necessary to distinguish them. Otherwise your query tool will not know which query you have in mind when you click the Send button.
In the present scenario, if you fail to include operation names for your individual query operations, your tool will most likely complain.
Mutation operations
Let’s shift into second gear. This time, we don’t want to passively extract data from the GraphQL server. We want to modify existing data or create new entries. This is why we are using a mutation operation.
Here’s an example:
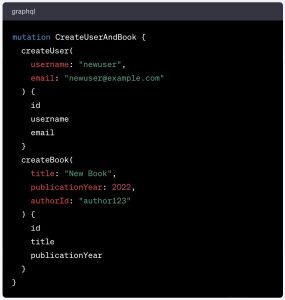
This starts with the the operation’s root type: mutation in the present case.
On the same line, we have the operation name: CreateUserAndBook. As we have only one mutation operation lined up, remember the operation name is optional.
This operation has two top level fields: createUser and createBook. So with this operation, we are creating two new entities in the server’s database: a new user and a new book.
Let’s look at the createUser top level field. To pass the data we want for the new user we are creating, we use arguments, listed in parentheses after the top level field name. Here, they are listed on separate lines, but as long as they are within the parentheses, that are attached to the top level field.
Then we list the fields we want the GraphQL server to return. This can be useful to check the new user has been created correctly.
Note that the fields we list don’t necessarily need to match the arguments we passed with the top level field. Here, we also include the id field, to see which id the app has assigned to our new user.
Likewise, with the second top level field, we include the id field, but not the authorId we listed in our top level field arguments.
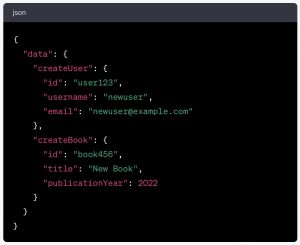
This mutation operation will return the following:
Subscription operations
The third operation root type we need to look at is subscription. With this operation, we can subscribe to real-time updates for new messages in a chat application, for instance. Here’s what the operation could look like:
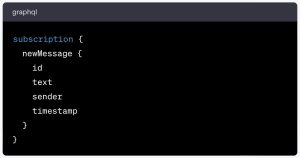
When a client app executes this subscription, the GraphQL server will push updates to the client whenever new messages are sent. The data returned will look something like this:
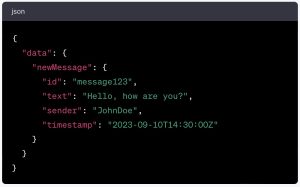
With a subscription operation, rather than a single immediate response, the GraphQL server will send individual responses whenever new messages are created.
Congratulations for making it all the way down this post… 😉
You now have all you need to start interacting with GraphQL servers.