Every GraphQL API has a schema. The schema is a detailed list of all the object types and operation types that exist on a given GraphQL server. You can see the schema as a dictionary describing the structure of the API. You can also see it as a map that will give you a bird’s eye view of the target API you want to test.
This is why understanding the GraphQL schema is essential if you want to do anything serious in GraphQL (yes, including hacking).
A GraphQL schema kinda works backwards, first describing the object types, with their individual fields, then listing the operation types (Query, Mutation and Subscription). The schema also lists the input types that are used to pass arguments to operation types. Finally, it defines the root schema type, that brings the whole schema together.
Here is an example of a GraphQL schema that represents information about books, authors, users, and messages, including query, mutation, and subscription operations:
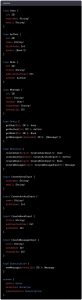
OK, so let’s break it down and take it step by step.
Object types
In the top section, we have four object types: User, Author, Book, and Message, each with their respective fields and relationships. Here are the first two:
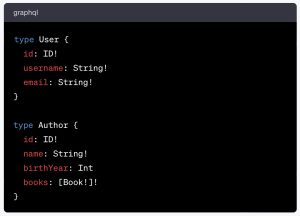
As you can see, each object type has an entry in the schema, with a list of the fields that can be queried and the data type of what they contain (ID, String, etc).
If you look at the whole schema, you may notice some nested objects. In particular, the Book object is referenced in a field of the Author object. And the Author object is referenced in a field of the Book object (when we’ll look into hacking techniques, you will see that such a cross reference scenario is a condition we would want to exploit when testing an API).
The Query type
After the object types, our example schema lists a Query type with various query fields to retrieve data about users, authors, books, and messages:
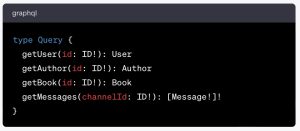
These are the fields we will use when writing our queries and sending them through to the API. As you can see, the schema indicates the arguments required for these fields (id or channelId in the present case), the data type of these arguments and the object type whose fields will be returned (User, Author, Book, and Message in our example).
The Mutation type
Further down, our example schema lists a Mutation type:
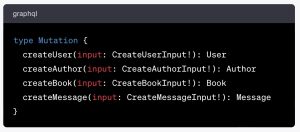
The Mutation type provides mutation operations (createUser, createAuthor, createBook and createMessage) for creating new users, authors, books, and messages.
You will notice these operations all have an Input argument, referencing Input types that we can use when we have several arguments to pass along with our request.
Input types
After the Mutation type, our schema lists a number of Input types (they are the ones used in the mutation operations described above). Here are the first two :
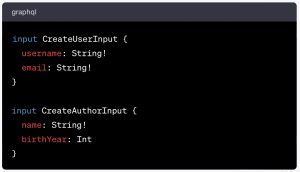
Input types like CreateUserInput, CreateAuthorInput, CreateBookInput, and CreateMessageInput are used as arguments for mutation operations to pass data when creating new records.
When using the CreateUserInput type, a Mutation operation passes the username and email fields.
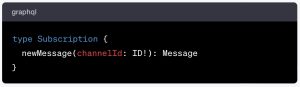
The Subscription type
Finally, there’s a Subscription type with a subscription operation called newMessage, allowing clients to subscribe to real-time updates for new messages in a specified chat channel (identified in the channelId argument).
There is only one subscription operation in our sample schema.
If you’re still uncomfortable with Query, Mutation and Subscription operations, I have a post right here on this topic.
The Schema type
At the bottom of our schema is the Schema type:
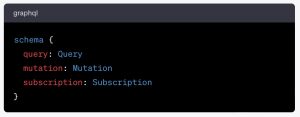
Here, we’re defining the root types for each of the three main operations:
query: Specifies that the root query operation is provided by theQuerytype.mutation: Specifies that the root mutation operation is provided by theMutationtype.subscription: Specifies that the root subscription operation is provided by theSubscriptiontype.
This schema type effectively ties together the different parts of the schema, indicating which types are responsible for handling queries, mutations, and subscriptions.
You can consider the schema type as the tree trunk of our schema, which branches out into the Query, Mutation and Subscription types, themselves branching out into smaller branches for the different object types they access. In this analogy, the different fields we can access using our GraphQL requests would be the leaves at the end of each branch, with the data we want to get back.
As a closing note and disclaimer: some of the material for this article was generated using ChatGPT (fact checked, clarified and largely completed by yours truly 😉).