As I was progressing along my API hacking learning path, OAuth 2.0 kept coming back as something I would have to get my head around at some point. Recently, I was testing an API in the scope of a Vulnerability Disclosure Program on Bugcrowd and OAuth was the authorization mechanism the API was using. It was time for me to finally get a proper understanding of this technology.
Googling OAuth 2.0 didn’t turn up the clear and factual explanation I was hoping for. So I embarked in writing the OAuth 2.0 piece I would have wanted to read.
OAuth 2.0 basics
According to ChatGPT, “OAuth 2.0 is a protocol that allows applications to access user data from another application without needing to know the user’s login credentials. It provides a secure and standardized way for users to grant permission to applications to access their data on their behalf”.
Let’s put this in an API perspective. Imagine an application that sends a query through an API to obtain a user’s personal details. The request needs to include a header with some sort of authorization token (a string of characters in the present case) that would allow the API to verify the app or user making the request is legit before sending back the requested data.
Why do we need this? Because APIs use stateless connections. This is different from how a web application works. A web application will generally open a new session when a user logs in, then send this user’s browser a cookie that will link every subsequent request to this user’s session. When the user logs out, the session is terminated and the cookie is removed.
An API doesn’t open user sessions and will treat every query received as an independent request. This means every query needs to include an authorization header to let the API know that the request is legit and can be processed safely.
The workflow is as follows:
– the user logs into the API through a login endpoint, generally including their username and password in the request body as authentication,
– if the username and password are valid, the API (or more specifically the authorization server used by the API) sends back an OAuth 2.0 access token in the response headers,
– in all subsequent requests, the user includes this token in an authorization header,
– the API checks for the presence and validity of this token before processing the request,
– if the token is valid, the API sends back the requested data,
– if the token is absent or invalid, the API will generally return a 401 Unauthorized response code.
Why use an OAuth 2.0 token rather than simply include the user’s credentials in all requests? First, to avoid revealing usernames and passwords (this is notably the case when the token issuer and the API using this token for authorization are not the same entity – but that’s a story for another post). Also, a token can be set to limit access to a certain type of data and can have a expiration date or time for added security.
In a video explaining how OAuth 2.0 tokens actually work, Aaron Parecki offers a great analogy. Suppose you show up at a hotel where you booked a room. You check in at the reception, fill in the registration card and show identification (the equivalent of logging into an API). The receptionist gives you a key card (the OAuth token). Every time you want to enter your room (access the API data), the lock checks the validity of your key card and unlocks the door. You don’t have to show ID every time you want to enter your room. The key card only lets you into your own room and not into anyone else’s room. And the key card won’t let you in once your stay is over.
I definitely recommend checking out Aaron’s video. It dates back a few years but it’s the best I’ve seen so far to explain how OAuth tokens work.
A practical example of OAuth
In the use case I mentioned in the introduction of this article, a supplier of payroll and HR services allows third party accounting companies (or back office service companies) to integrate these services into their own offering through an API. These accounting companies can therefore provide these services to their own customers (think small businesses and local shops) by integrating them into their own web site.
An API endpoint allows an accounting company to register their client into the system. To do this, the accounting company will send an API call including the client’s details in the request body. They will also include their API key in a request header to let the API server check they are a legit customer of the API provider (note that such customers will in some cases identify using a client_id and a client_secret instead).
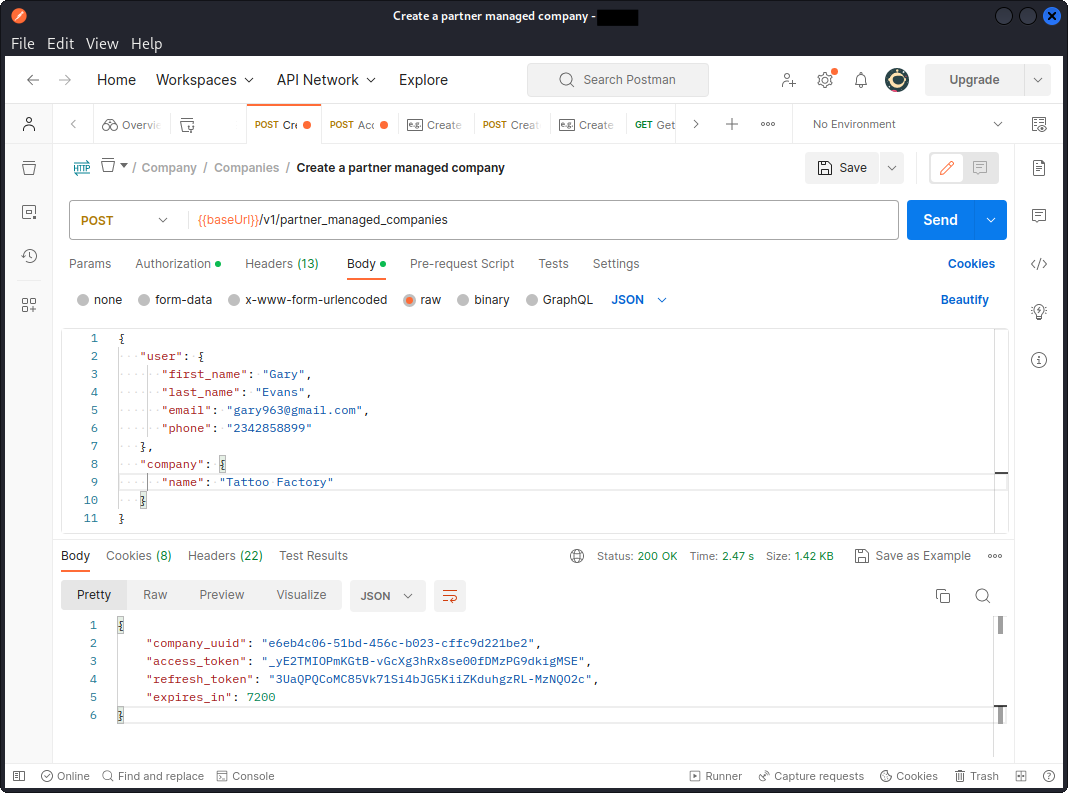
The API replies with a company_uuid that now identifies Tattoo Factory in the system, an access_token that allows this client to send queries through the API, as well as a refresh_token that Tattoo Factory can use to get a new access_token when the initial one has expired. Notice the expires_in key in the response body, that indicates the access_token will expire in two hours (7200 seconds).
Now when Tattoo Factory wants to check their company data in the system, a different API endpoint is used, that returns the required info.
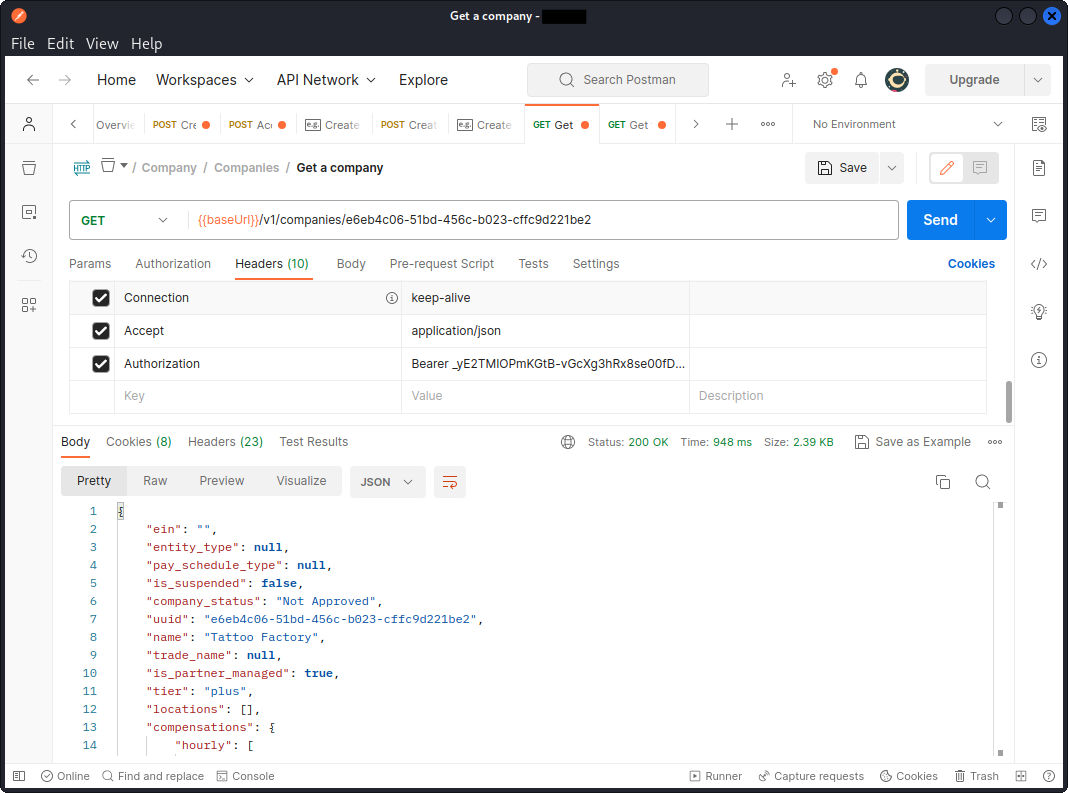
Notice how Tattoo Factory’s company_uuid is used in the URL path to indicate which client’s data is being requested and the access_token used in the Authorization request header.
If Tattoo Factory attempted to access their user data after their access_token expired, they would have to ask for a new token. Yet another API endpoint would then be queried using the refresh_token, as well as the client_id and client_secret. The API would check Tattoo Factory is still a registered customer before issuing an updated access_token.
If all this still seems confusing, what you need to take away is that when you are testing an API and you see items like client_id, client_secret, access_token, or refresh_token involved, this is a sign the API is most likely using an OAuth 2.0 server for authorization. You should also see references to OAuth 2.0 in the API documentation, if you have access to it.
What’s in an OAuth 2.0 token?
You will see two main token implementations. In the first case, the information on the token’s validity and scope is stored server side and the token itself is just a string of characters that lets the API connect to the data it has in store. In such a scenario, the token will look something like this:
6I5wYTLDecu4eGWlRw9YmnuMAPW-TMgGoY4Kve-2auo
As a hacker, there isn’ t much point trying to decode the string, as no data is stored in the token itself. You best bet is to look for exposed access tokens that may have been left in the source code of web pages or in Github repositories (and hope the token hasn’t expired).
In the second scenario, the token actually embarks data on the user making the request and on the validity of the token. It may even in some cases include user credentials. In such a scenario, it will often be a JSON Web Token (JWT) that will look something like this:
eyJhbGciOiJIUzUxMiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiJlZHdAemVyb2RheWhhY2tlci5jb20iLCJpYXQiOjE2NjU3NTM4NTYsImV4cCI6MTY2NTg0MDI1Nn0.SbZ3F1kmuntmjy8aJQFj5xUZL_RelJE4bCfWAHUVzbfxyWGIzQhq5zx-CF3voRz3xxHWfY5H1GxjbdedRjQdfw
In this scenario, as a hacker, it is definitely works trying to decode a token you may have come across during recon, as this may reveal useful data on a user or a pattern that may let you forge a rogue token to access the API. If you want to know more about this, I have a 3-part series on hacking JWTs that starts with this post.
Closing thoughts
This article is admittedly more of a ‘note to self’ post bringing together what I know about OAuth 2.0 for future reference, so you may want to check back regularly as I may update it as my understanding progresses. If you believe anything is inaccurate or missing, feel free to drop me a note in the comments.
And if you want to take things further with OAuth 2.0, here are some of my favorite resources:
– Aaron Parecki’s OAuth web site,
– What is OAuth (The Modern Guide), by FusionAuth,
– What is OAuth 2.0? by authO,
– And from a hacker’s perspective, definitely check out PortSwigger’s section on OAuth 2.0 authentication vulnerabilities.
Enjoy!