Regular expressions (or regex) offer a way to look into a text file, a form, or a command line output and locate strings that match a specific pattern. This allows you to extract emails, phone numbers, keys that match a given structure, etc. You can think of regex as a search function on steroids.
Regex can also be used by web developers to check the data entered into fields in online forms is correctly formatted (ex. phone or address fields).
Closer to our line of work, regex can be used in Burp Suite to separate the content of a text file containing a list of emails and corresponding passwords into two separate matching lists (and if you’ve been practicing with the vAPI vulnerable app, this should trigger a buzz).
Most screen shots in this post were taken using regex101.com, a great tool which allows you to type a regex, then test different strings against it.
Also, note that this post uses the Extended Regular Expression (ERE) syntax. If you want to know more about Basic Regular Expression (BRE) and Extended Regular Expression (ERE), I have a full post on this topic.
Matching a given string
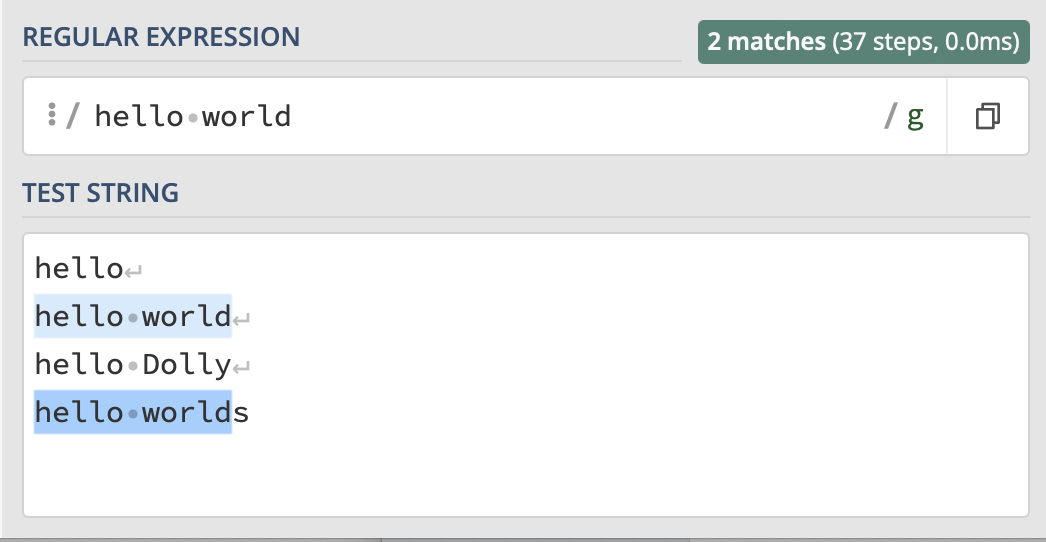
In its simplest form, a regex is just a string of characters of your choice. In the example below, you can see that only this exact string matches, including the space between hello and world. If a given line of text contains more, the match will be restricted to the string we are searching for.
Character sets
In many cases, you will not want to match an exact given string, but more likely a given structure. Say you want to match a word with different possible first letters. When typing the corresponding regex, you need to replace the first letter by a character set. To do this, use brackets as in the example below.
[a-z] means you want to match any lowercase letter. You could also match uppercase letters with [A-Z] and digits with [0-9].

As you can see, the first two strings match. The third one will only include one character before the ing string. The fourth one doesn’t match at all, as the first letter is not a lowercase.
Repeating characters from a character set
Character sets can stand in for more than one character. To specify a number of characters, use curly brackets as shown here:
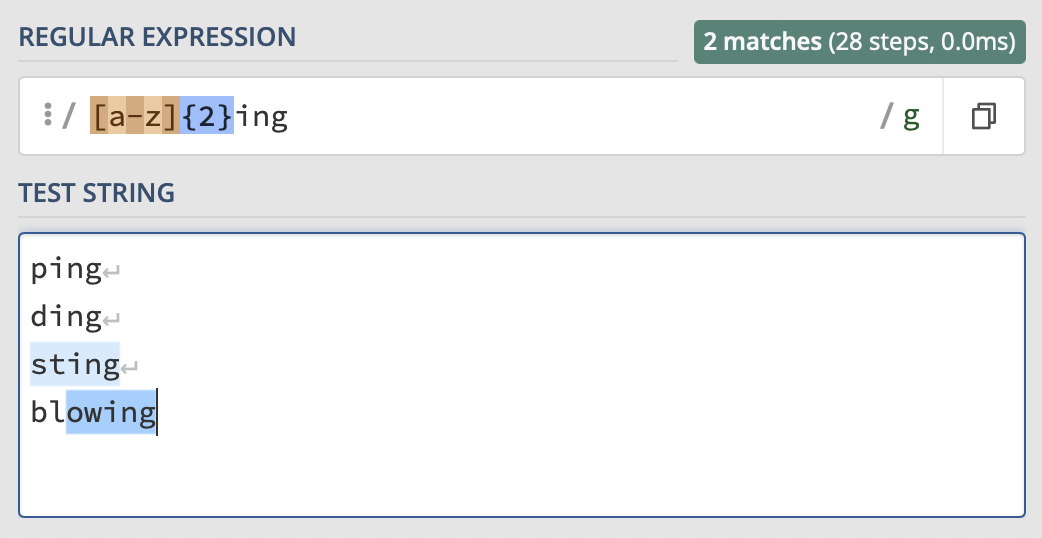
Here, the regex matches the ing string with the two (and only two) preceding characters.
You can specify a range using {2,4}.
If you want 3 or more characters, you can use {3,}.
If you want zero or one character, use ?
If you want one or more characters, use +
Matching any character
Suppose you want to match any character. You can do this by using a period (.) as seen below.
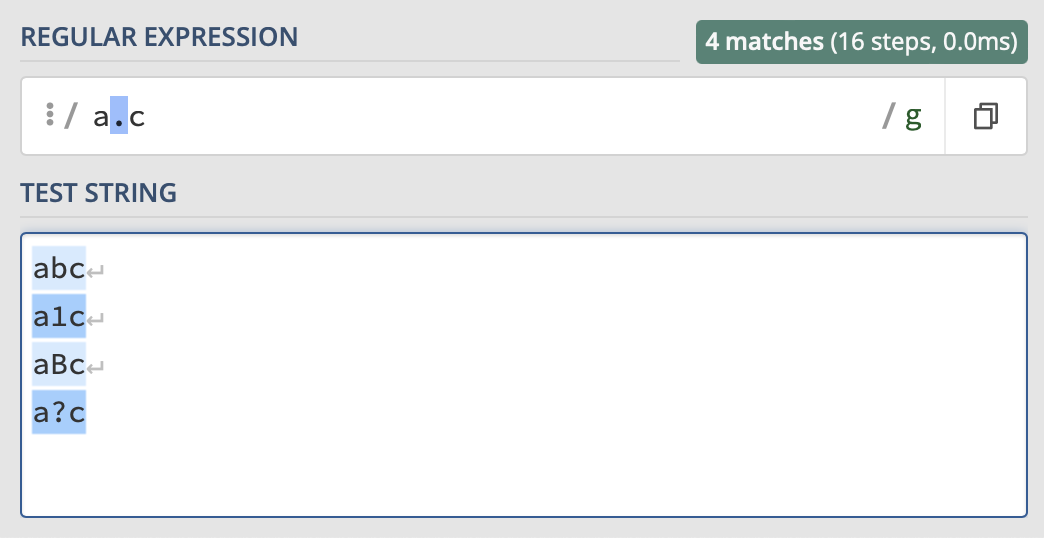
This replaces any character except the new line character.
Special characters
As we have seen, characters such as the following all have a special meaning: [ ] { } . ? +
They are called special characters.
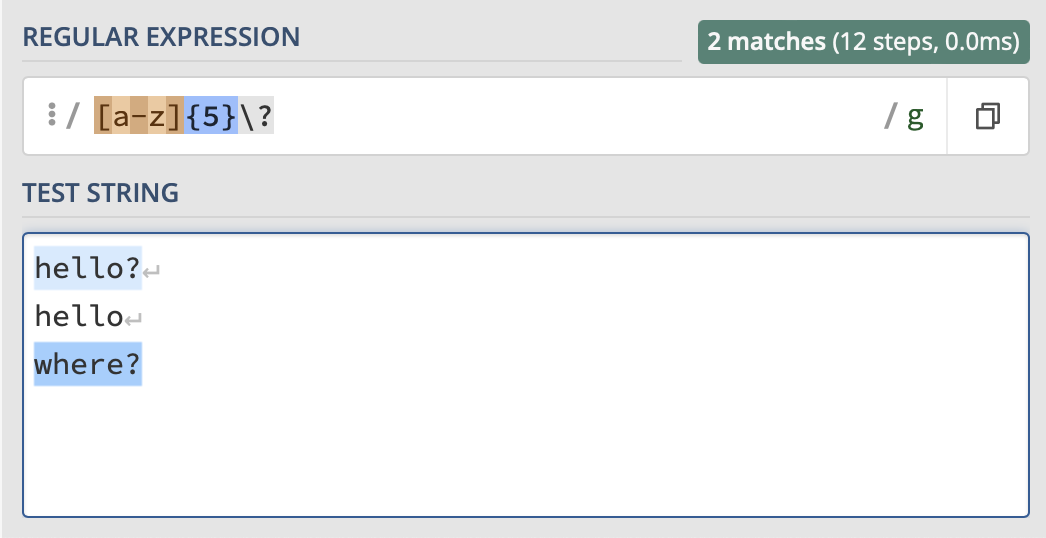
Note that if you want to use them as regular characters, you will need to escape them with a backslash, as seen below.
Metacharacters
These are characters that have a given function when typed with a backslash preceding them (unlike special characters that have a special function by default and that you need to escape with a backslash if you want to use them as standard characters).
Exampes of metacharacters are \t to replace a tab, \d to replace any digit, or \w to replace any word character (this means uppercase and lowercase letters, as well as digits and the underscore character).
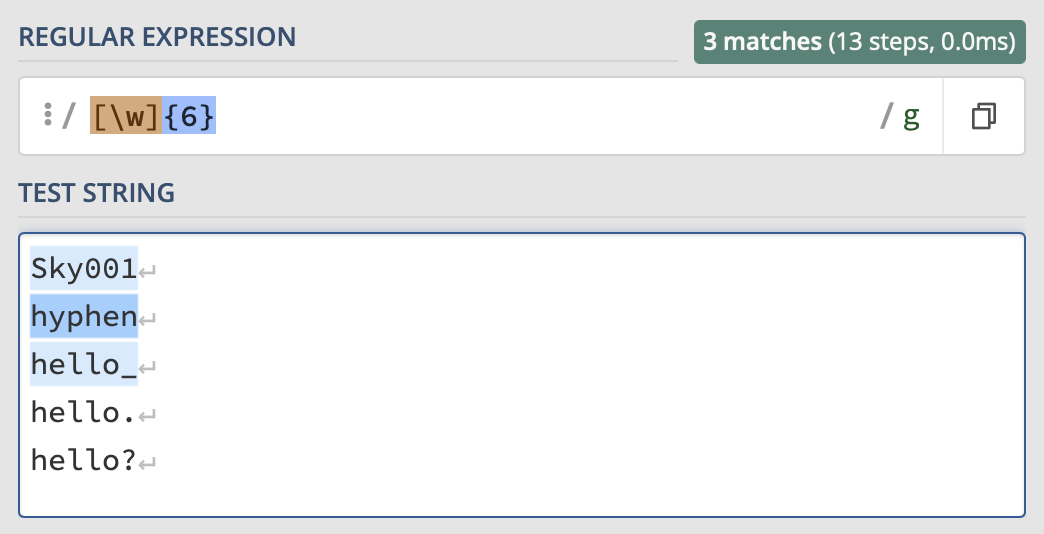
In the example above, note that both of these syntaxes are valid:
[\w]{6}
\w{6}
Here is a list of special characters and metacharacters taken from the quick reference panel in regex101.com.

Searching for a set of words
Another useful special character is the pipe symbol | that lets you specify a list of words or expressions to match. Note that the list needs to be in parentheses, as seen below:

Starting or ending a string
The caret symbol (^) placed before an expression indicates that, in order to match, the given expression needs to be at the beginning of a line. If the expression is elsewhere in the line, then it doesn’t match.
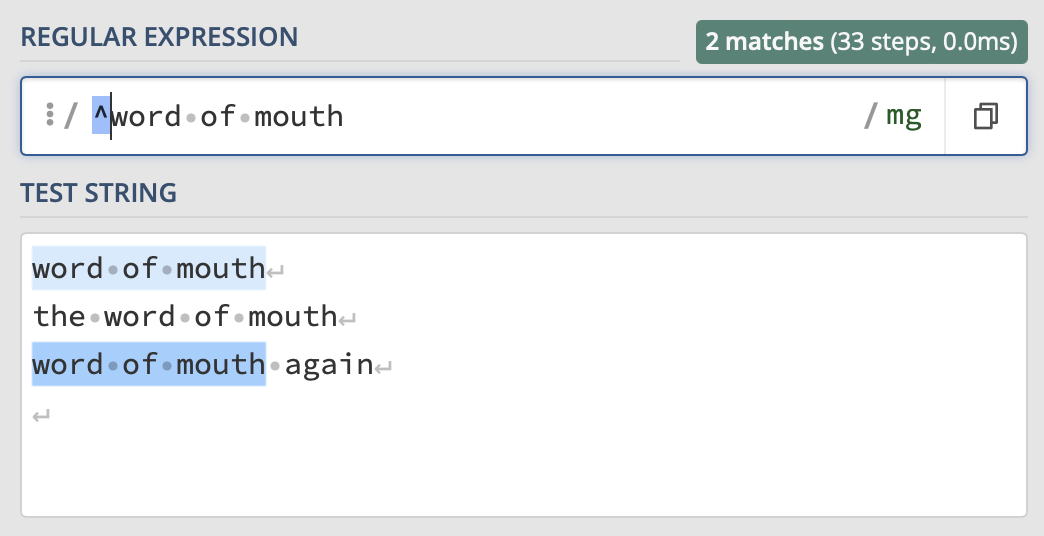
Likewise, a $ positioned after an expression indicates that, in order to match, the given expression needs to be at the end of a line. If the expression is elsewhere in the line, then it doesn’t match.
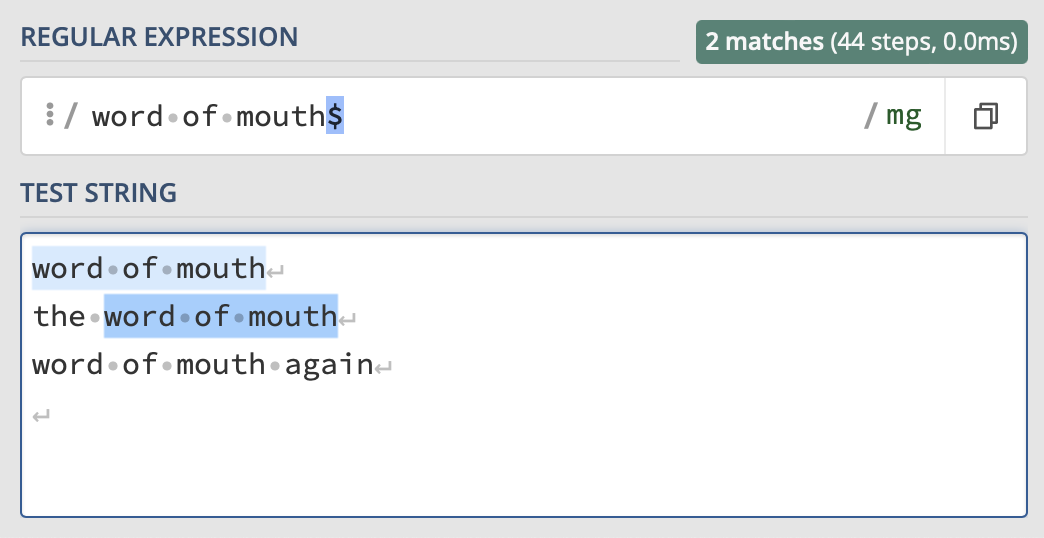
Matching an email
So now you have the basic rules. Let’s put this in practice.
Here is a regex I would use if I wanted to match all emails from a given text or list:
[a-zA-Z0-9._]+@[a-zA-Z]+\.[a-zA-Z.]{2,}
[a-zA-Z0-9._]+
This part says we want to match a string of any number of lowercase letters, uppercase letters, digits, as well as periods and underscores.
@
Then we want to match the @ symbol.
[a-zA-Z]+
This part refers to the domain name, which can be of any length of lowercase or uppercase letters.
\.
Then we want a period between the domain name and the extension. Here, we escape the period as we want to use it as a standard character and not as a special character.
[a-zA-Z.]{2,}
Finally, we want the extension to be any combination of letters and periods, with at least two characters (.eu .com .co.uk .online and so on).
Let’s try it out on a text file, using the following command:
cat email.txt | grep -oE "[a-zA-Z0-9._]+@[a-zA-Z]+\.[a-zA-Z.]{2,}"
This is what we get:

Matching a US phone number
Let’s match phone numbers in this format: (345) 647-3232
I would use this regex:
\([0-9]{3}\) [0-9]{3}-[0-9]{4}
\(
This indicates we want to match an open parenthesis. Remember the ( character is a special character, so we need to escape it with a backslash if we want to use is as a standard character.
[0-9]{3}
This part says we want any combination of three digits.
\)
Now we are closing the parenthesis.
[0-9]{3}-
After the space, we want any combination of three digits, followed by a dash (the dash isn’t a special character so doesn’t need to be escaped).
[0-9]{4}
Finally, we and ending our regex with a combination of any four digits.
Let’s try it out using the following command:
cat test.txt | grep -oE "\([0-9]{3}\) [0-9]{3}-[0-9]{4}"
This is what we get:

Separating a list of emails and passwords
We can also use regex in Burp Suite. Suppose we have obtained a list of emails and passwords in a text file. Each line of the file contains an email and the corresponding password, separated by a comma.
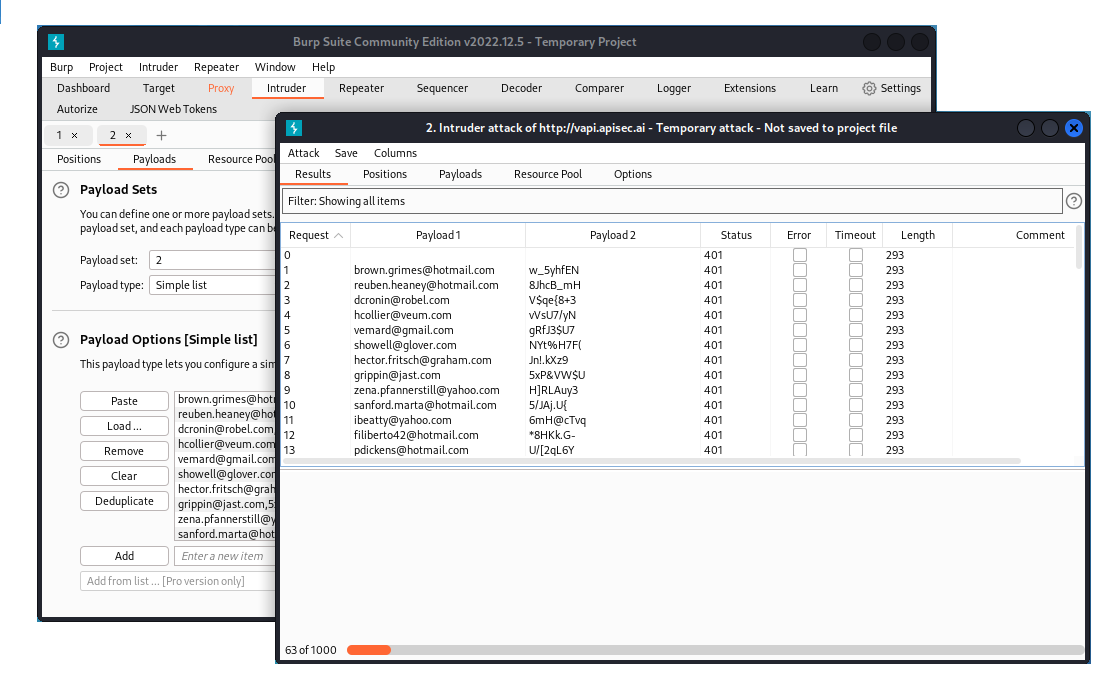
If we want to use these emails and passwords on two different positions in a pitchfork attack in Burp Intruder, this is how we would do it:
In the Payloads tab, go to the Payload Options section and load the file into both payload sets.
Now for the first set (for emails), go to the Payload Processing section, add a new rule and choose Match/replace. In Match regex: type ,.*
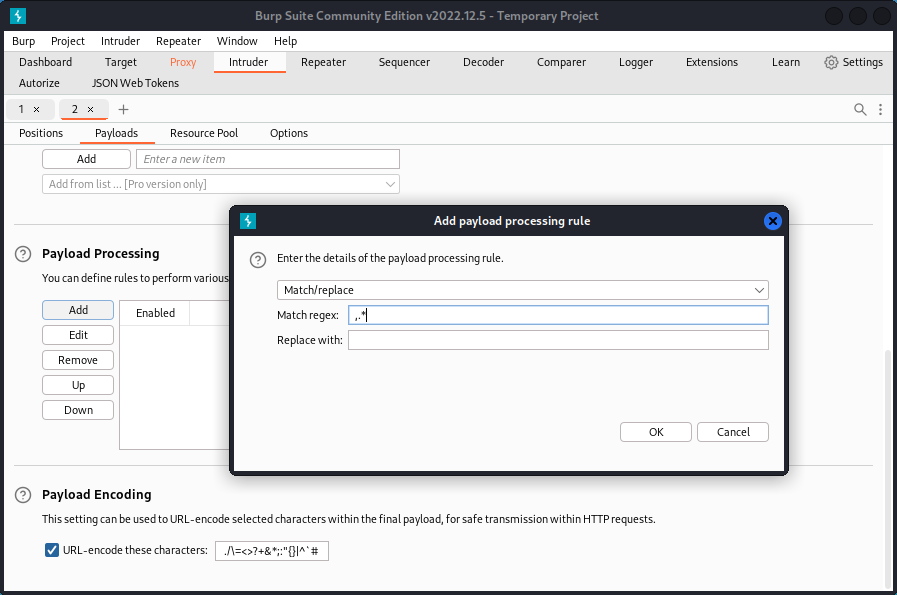
This means we want to select the comma as well as any following string of any characters (except the new line character).
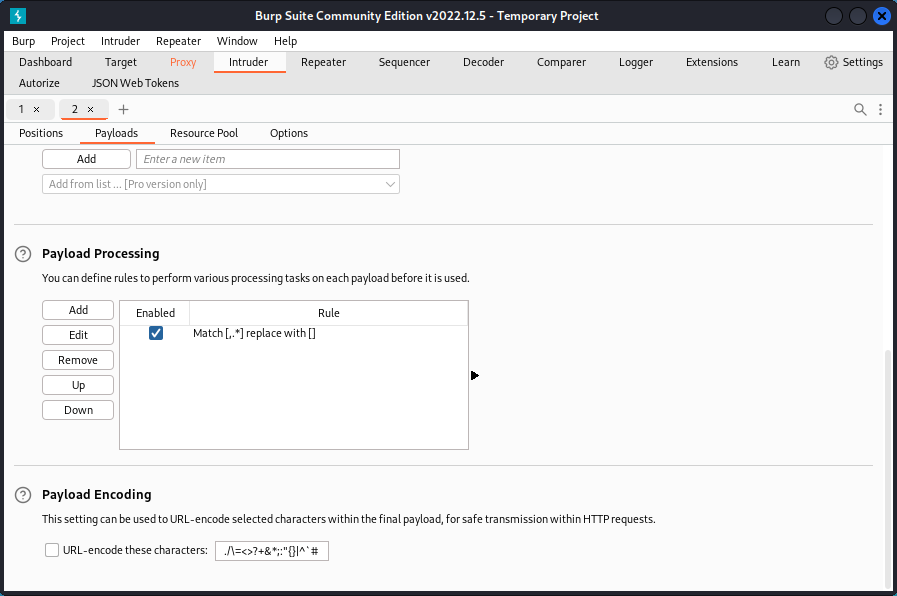
Leave the Replace with field empty. This will select and remove the comma and what comes after, leaving only the email address.
Do the same for the second set (for passwords), but this time use this regex: .*,
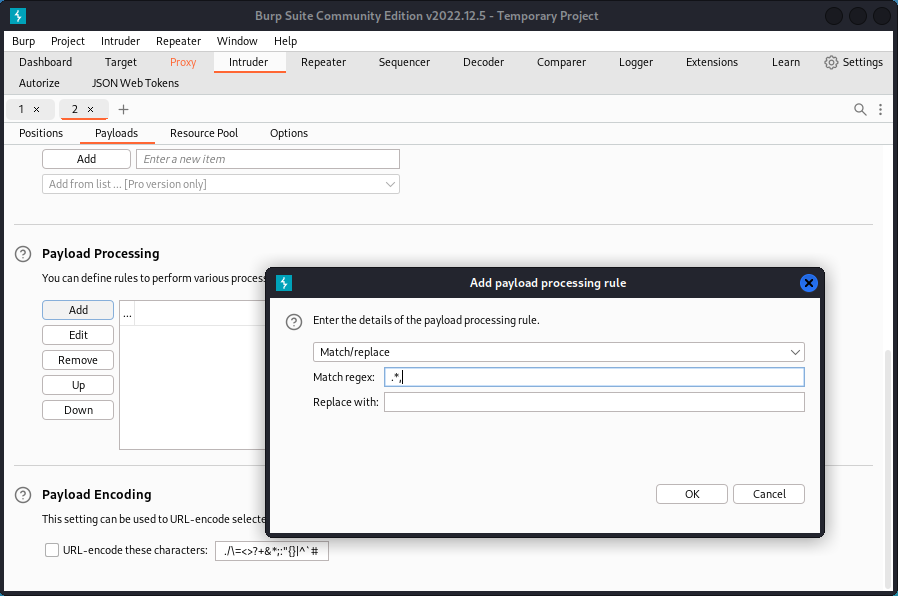
This will select and remove the comma and whatever comes before, leaving only the password.
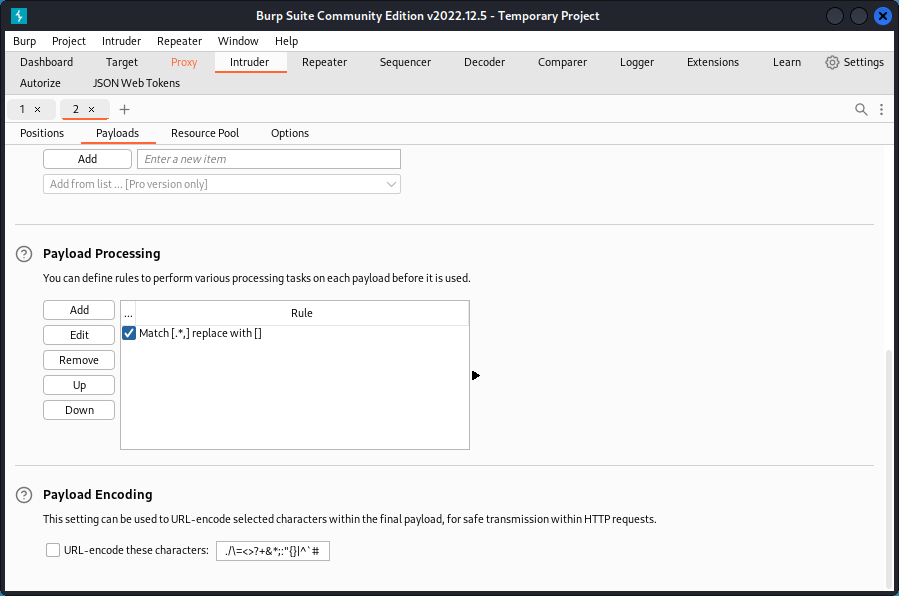
OK, so now we have the list of emails in the first position and the list of passwords in the second position.
If you run the attack, you will see that Burp Intruder tests all email and password combinations, using the emails for Payload 1 and corresponding passwords for Payload 2.
Taking things further
Here are two resources that I strongly recommend you check out:
regex101.com, as mentioned above, is a great tool to help you write a regex and test different strings against it.
regexr.com is another useful tool that takes a regex and breaks it down into all of its components, giving an explanation of what each component does.
Finally, if you want a more thorough explanation of regex, check out The Net Ninja’s video tutorial.
A lot of what I know about regex actually comes from this tutorial.
Enjoy!